PDF को छवि के रूप में सहेजें
इस बार सहेजे गए PDF को छवि फ़ाइल के रूप में सहेजने का तरीका समझाया गया है।
"PDF से छवि निकालें" क्रिया का विवरण
इस बार हम "PDF से छवि निकालें" क्रिया का उपयोग करेंगे।
क्रिया में निम्नलिखित पैरामीटर होते हैं:
| पैरामीटर का नाम | मान |
|---|---|
| PDF फ़ाइल | छवि के रूप में निकालने के लिए लक्षित PDF फ़ाइल का पथ |
| निकालने का पृष्ठ | सभी पृष्ठों को प्रिंट करना है या पृष्ठ-वार प्रिंट करना है, इसे चुनें |
| छवि का नाम | निकाली गई छवि की फ़ाइल का नाम |
| छवि का सहेजने का स्थान | निकाली गई छवि को सहेजने का पथ |
कॉपी और पेस्ट करके कार्यान्वयन
इस बार एक उदाहरण के रूप में, सार्वजनिक दस्तावेज़ों में सहेजे गए PDF फ़ाइल से छवि के रूप में निकाली गई फ़ाइल को उसी फ़ोल्डर में सहेजने का प्रवाह तैयार किया गया है।
निम्नलिखित कोड को कॉपी करें और Power Automate Desktop के संपादन स्क्रीन में पेस्ट करें, जिससे लक्षित क्रिया जोड़ी जाएगी।
Pdf.ExtractImagesFromPDF.ExtractImages PDFFile: $'''C:\\Users\\Public\\Documents\\target.pdf''' ImagesName: $'''converted''' ImagesFolder: $'''C:\\Users\\Public\\Documents'''
Power Automate Desktop को संचालित करके कार्यान्वयन
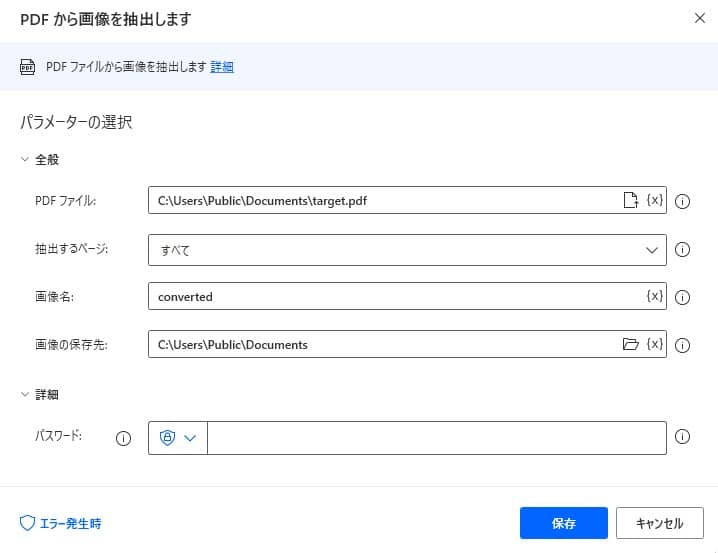
"क्रिया खोजें" से, "PDF से छवि निकालें" दर्ज करें।
पैरामीटर को निम्नलिखित रूप में सेट करें
पैरामीटर का नाम मान PDF फ़ाइल C:\Users\Public\Documents\target.pdf निकालने का पृष्ठ सभी छवि का नाम converted छवि का सहेजने का स्थान C:\Users\Public\Documents इसे चलाने से, निर्दिष्ट PDF फ़ाइल से निकाली गई छवि फ़ाइल सहेजी जाएगी।
संभावित अपवाद
संभावित त्रुटि तब होती है जब PDF पासवर्ड से सुरक्षित होता है। यदि PDF पासवर्ड से सुरक्षित है और पासवर्ड सेट नहीं किया गया है या पासवर्ड गलत है, तो त्रुटि होगी।
इसके अलावा, यदि फ़ाइल पथ गलत है या PDF से छवि डेटा को सही से प्राप्त नहीं किया जा सका, तो त्रुटि हो सकती है।
यदि छवि निकालना अनिवार्य नहीं है, तो ब्लॉक प्रोसेसिंग को लागू करने की सलाह दी जाती है।