PDF を画像として保存する
今回は保存している PDF を、画像ファイルとして保存する方法を解説します。
「PDF から画像を抽出します」アクションの詳細
今回使用するのは、「PDF から画像を抽出します」というアクションです。
アクションは以下のパラメーターを持ちます。
| パラメーター名 | 値 |
|---|---|
| PDF ファイル | 画像として抽出する対象の PDF ファイルのパス |
| 抽出するページ | 全てのページを印刷するのか、ページ単位で印刷するのかを選択 |
| 画像名 | 抽出した画像のファイル名 |
| 画像の保存先 | 抽出した画像を保存するパス |
コピーアンドペーストで実装
今回はサンプルとして、パブリックのドキュメントに保存されている PDF ファイルから、画像として抽出したファイルを同一フォルダに保存するフローを用意しました。
以下のコードをコピーし、Power Automate Desktop の編集画面に貼り付けることで、対象のアクションが追加されます。
Pdf.ExtractImagesFromPDF.ExtractImages PDFFile: $'''C:\\Users\\Public\\Documents\\target.pdf''' ImagesName: $'''converted''' ImagesFolder: $'''C:\\Users\\Public\\Documents'''
Power Automate Desktop を操作して実装
「アクションの検索」から、「PDF から画像を抽出」と入力します。
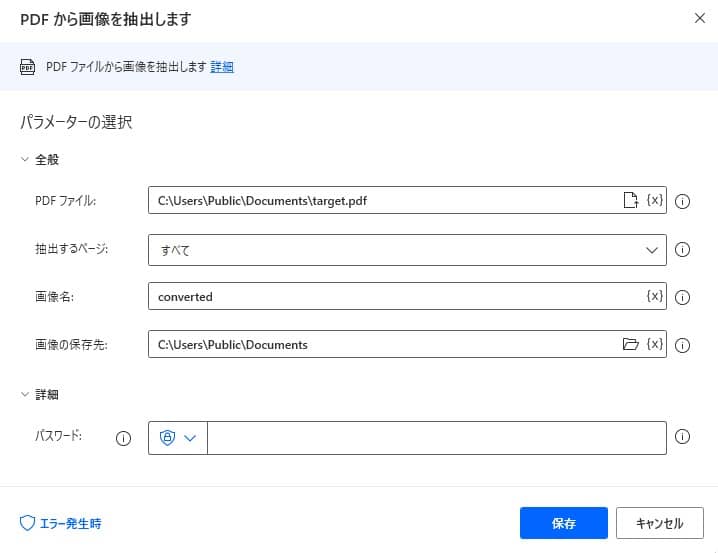
パラメーターを以下のように設定します
パラメーター名 値 PDF ファイル C:\Users\Public\Documents\target.pdf 抽出するページ すべて 画像名 converted 画像の保存先 C:\Users\Public\Documents 実行することで、指定した PDF ファイルから抽出した画像ファイルが保存されます。
起こりうる例外
起こりうるエラーとしては、PDF にパスワードがかかっている場合です。パスワード付きの PDF であるにもかかわらず、パスワードが未設定の場合や、パスワードが異なっていた場合にはエラーとなります。
その他、各ファイルパスが間違っている場合や、PDF から画像データをうまく取得できなかった場合にエラーとなる場合があります。
画像の抽出が必須ではない場合は、ブロック処理を実装しておくことをおすすめします。